With the popularity and proliferation of iSCSI, a lot of questions are being asked regarding iSCSI performance and when to consider deployment.
iSCSI performance is one of the most misunderstood aspects of the protocol. Looking at it purely from a bandwidth perspective, Fibre Channel at 2/4Gbit certainly appears much faster than iSCSI at 1Gbit. However, before we proceed further lets define two important terms: Bandwidth and Throughput
Bandwidth: The amount of data transferred over a specific time period. This is measured in KB/s, MB/s, GB/s
Throughput: The amount of work accomplished by the system over a specific time period. This is measured in IOPS (I/Os per second), TPS (transactions per second)
There is a significant difference between the two in that Throughput has varying I/O sizes which have a direct effect on Bandwidth. Consider an application that requires 5000 IOPS at a 4k block size. That translates to a bandwidth of 20MB/s. Now consider the same application but at a 64k size. That's a bandwidth of 320MB/s.
Is there any doubt as to whether or not iSCSI is capable of supporting a 5000 IOP, 20MB/s application? How about at 5000 IOPs and 40MB/s using a SQL server 8k page size?
Naturally, as the I/O size increases the interconnect with the smaller bandwidth will become a bottleneck sooner than the interconnect with the larger one. So, I/O size and application requirements makes a big difference as to when to consider an iSCSI deployment.
If you are dealing with bandwidth intensive applications such as backup, video/audio streaming, large block sequential I/O Data Warehouse Databases, iSCSI is probably not the right fit, at this time.
Tests that we have performed internally, as well, as tests performed by 3rd party independent organizations such as the Enterprise Storage Group confirm that iSCSI performance difference between FC and iSCSI is negligible when deployed with small block OLTP type applications. Having said that, there are also documented tests conducted by a 3rd party independent organization, Veritest, where iSCSI outperformed an equivalent array identically configured with FC using Best Practices documentation deployed by both vendors, in conjuction with an OLTP type of workload.
At the end of the day, always remember that the application requirements dictate protocol deployment.
Another question that gets asked frequently is whether or not iSCSI is ready for mission critical applications.
iSCSI has come a long way since 2003. The introduction of host-side clustering, multipathing support and SAN booting capabilities from various OS and storage vendors provide a vote of confidence that iSCSI can certainly be considered for mission critical applications. Additionally, based on deployments, Netapp has proven over the past 3 years, that a scalable, simple to use array with Enterprise class reliability when coupled with the above mentioned features can safely be the iSCSI platform for mission-critical applications. Exchange is a perfect example of a mission critical application (it is considered as such by lots of Enterprises) that is routinely deployed over iSCSI these days.
Wednesday, May 03, 2006
Tuesday, May 02, 2006
Dynamic Queue Management
When we (Netapp) rolled out Fibre Channel support almost 4 years ago, one of our goals was to simplify the installation, configuration, data and protocol management as well as provide deep application integration. In short, we wanted to make sure the burden does not fall squarely on the shoulder of the Administrator to accomplish routine day to day tasks.
One of the things we paid particularly attention to, was Host side and Target side Queue Depth management. Setting host Queue depths is a much more complicated process than the various disk subsystem vendors documentation make it to be and requires specific knowledge around application throughput and response times in order to decide what the appropriate Host Queue Depth should be set to.
All SAN devices suffer from Queue Depth related issues. The issue is that everybody parcels out finite resources (Queues) from a common source (Array Target Port) to a set of Initiators (HBAs) that consider these resources to be independent. As a result, on occasion, initiators can easily monopolize I/O to a Target Port thus starving other initiators in the Fabric.
Every vendor documentation I've seen, explicitly specifies what the host setting of the Host Queue Depth setting should be. How is that possible when in order to do this you need to have knowledge of the application's specific I/O requirements and response rime? Isn't that what Little's Law is all about (N=X * R)?
It's simply a "shot in the dark" approach hoping that the assigned queue depth will provide adequate application performance. But what if it doesn't? Well, then, a lot of vendors will give it another go...Another "shot in the dark". In the process of setting the appropriate Host Queue Depth, and depending on the OS, they will edit the appropriate configuration file, make the change, and ask the application admin to take an outage and reboot the host.
The above procedure is related to two things: a) Poor Planning without knowing what the Application requirements are b) Inadequate protocol management features
To address this challenge we decided to implement Dynamic Queue Management and move Queue Depth management from the Host to the Array's Target Port.
So what is Dynamic Queue Management?
Simply put, Dynamic Queue Management manages queue depths from the Array side. By monitoring Application response times on a per LUN basis, and QFULL conditions it dynamically adjusts the Queue Depth based on the application requirements. In addition, it can be configured to:
One of the things we paid particularly attention to, was Host side and Target side Queue Depth management. Setting host Queue depths is a much more complicated process than the various disk subsystem vendors documentation make it to be and requires specific knowledge around application throughput and response times in order to decide what the appropriate Host Queue Depth should be set to.
All SAN devices suffer from Queue Depth related issues. The issue is that everybody parcels out finite resources (Queues) from a common source (Array Target Port) to a set of Initiators (HBAs) that consider these resources to be independent. As a result, on occasion, initiators can easily monopolize I/O to a Target Port thus starving other initiators in the Fabric.
Every vendor documentation I've seen, explicitly specifies what the host setting of the Host Queue Depth setting should be. How is that possible when in order to do this you need to have knowledge of the application's specific I/O requirements and response rime? Isn't that what Little's Law is all about (N=X * R)?
It's simply a "shot in the dark" approach hoping that the assigned queue depth will provide adequate application performance. But what if it doesn't? Well, then, a lot of vendors will give it another go...Another "shot in the dark". In the process of setting the appropriate Host Queue Depth, and depending on the OS, they will edit the appropriate configuration file, make the change, and ask the application admin to take an outage and reboot the host.
The above procedure is related to two things: a) Poor Planning without knowing what the Application requirements are b) Inadequate protocol management features
To address this challenge we decided to implement Dynamic Queue Management and move Queue Depth management from the Host to the Array's Target Port.
So what is Dynamic Queue Management?
Simply put, Dynamic Queue Management manages queue depths from the Array side. By monitoring Application response times on a per LUN basis, and QFULL conditions it dynamically adjusts the Queue Depth based on the application requirements. In addition, it can be configured to:
- Limit the number of I/O requests a certain Initiator sends to a Target Port
- Prevent initiators from flooding Target ports while starving other initiators from LUN access
- Ensures that initiators have guaranteed access to Queue resources
With Dynamic Queue Management, Data ONTAP calculates the total amount of command blocks available and allocates the appropriate number to reserve for an initiator or a group of initiators, based on the percentage you specify (0-99%). You can also specify a reserve Queue Pool where an initiator can borrow Queues when these are needed by the application. On the host side, we set the Queue Depth to its maximum value.
The benefit of this practice is, that it take the guessing game out of the picture and guarantees that the application will perform at its maximum level without unnecessary host side reconfigurations, application shutdowns or host reboots. Look Ma', No Hands!!!
Several of our competitors claim that we're new to the FC SAN market. While I will not disagree, I will augment that statement by saying that we're also...wiser and we've addressed challenges in a 4 year span that others haven't since 1997. After all, there's nothing mystical or cryptic about implementing a protocol that's been around for several years.
Improving Back-End Storage Resiliency
Some of the most important factors in obtaining High Availability are redundancy, fault tolerance and resiliency. While almost all high-end disk subsystems provide these capabilities, the same can not be said for all mid-tier disk arrays.
A typical mid-tier array consists of a couple of Storage Controllers or Storage Processors which are connected to one or more Disk Enclosures thru Fibre Channel Arbitrated Loop (FC-AL). Inside each Disk Enclosure is a backplane which the disks are connecting to. In addition, each Disk Enclosure is connected to Dual independent FC-AL loops and contains a Port Bypass Circuit (PBC). This type of Disk Enclosure is called a JBOD (Just a Bunch of Disks).
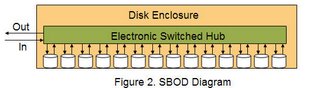
Because innovation doesn't only allow us to solve new problems but also allows us to solve old problems, a new technology surfaced around 2001 in the form of embedded FC switches (also called Switch on a Chip) in the Disk Enclosures that address the above issues. Such type of an Enclosure is called an SBOD (Switched Bunch of Disks). The embedded switches allow for each drive to have an individual FC-AL connection and be the only element in the loop thus providing faster arbitration and lower latency. In addition, the embedded switches provide the ability to isolate drive chatter without endagering the Loop. Performance and scalability are also direct beneficiaries of this technology. An SBOD, can deliver up to 50% more performance over JBOD mostly due to the fact that the bandwidth is not shared as well as due to the crossbar architecture deployed inside the embedded switches. Scalability has also improved outside of the Disk Enclosure by being able to increase the number of drives and Disk Enclosures that are connected to the FC-AL loop(s) on the Storage Controller.
Network Appliance was one of the first vendors to recognize the benefits of such technology and have been providing our customers with increased storage resiliency across all of our product line for almost 3 years now.
A typical mid-tier array consists of a couple of Storage Controllers or Storage Processors which are connected to one or more Disk Enclosures thru Fibre Channel Arbitrated Loop (FC-AL). Inside each Disk Enclosure is a backplane which the disks are connecting to. In addition, each Disk Enclosure is connected to Dual independent FC-AL loops and contains a Port Bypass Circuit (PBC). This type of Disk Enclosure is called a JBOD (Just a Bunch of Disks).


Because innovation doesn't only allow us to solve new problems but also allows us to solve old problems, a new technology surfaced around 2001 in the form of embedded FC switches (also called Switch on a Chip) in the Disk Enclosures that address the above issues. Such type of an Enclosure is called an SBOD (Switched Bunch of Disks). The embedded switches allow for each drive to have an individual FC-AL connection and be the only element in the loop thus providing faster arbitration and lower latency. In addition, the embedded switches provide the ability to isolate drive chatter without endagering the Loop. Performance and scalability are also direct beneficiaries of this technology. An SBOD, can deliver up to 50% more performance over JBOD mostly due to the fact that the bandwidth is not shared as well as due to the crossbar architecture deployed inside the embedded switches. Scalability has also improved outside of the Disk Enclosure by being able to increase the number of drives and Disk Enclosures that are connected to the FC-AL loop(s) on the Storage Controller.
Network Appliance was one of the first vendors to recognize the benefits of such technology and have been providing our customers with increased storage resiliency across all of our product line for almost 3 years now.
Monday, May 01, 2006
RAID-DP vs RAID 10 protection
On average, disk capacity is doubling every 15 to 18 months. Unfortunately, disk error correction code (ECC) capabilities have not kept pace with that capacity growth. This has a direct impact on data reliability over time. In other words, disks are about as good as they are going to get, but are now storing eight times the amount of data they did just four years ago. All storage system vendors are affected. A double-parity configuration shields customers against multiple drive failures for superior protection in a RAID group.
- Roger Cox, Chief Analyst - Gartner, Inc
With the advent of SATA drives and their proliferation in the Enterprise the above comment is quite significant. Most vendors to date, use a RAID 1 or RAID 10 protection schemes to address the shortcomings of PATA/SATA drives. What we do know about these drives is that they have low MTBFs and the Bit Error Rate is 10^14. That's approximately 1 bit error per 11.3TB. Compare this to FC drives at 10^15 with 1 bit error per 113TB!!!
Drive reliability is a function of two elements: MTBF (Mean Time Between Failures) and BER (Bit Error Rate). Historically ATA drives have demonstrated lower reliability than SCSI or FC drives and this has nothing to do with the interface type but rather it's directly related to the components used (media, actuator, motor etc) in the drive.
As I mentioned above, PATA/SATA drives are getting deployed in abundance these days in the Enterprise as a lower cost medium to host non-mission critical apps, as well as, serving as targets/Snap areas holding Snapshoted data for applications residing on higher performance disks. In addition, they are deployed in Tiered Storage approaches either within the same array or across arrays of different costs.
In order to protect against against potential Double disk failures in PATA/SATA configurations, several vendors propose RAID 1 or RAID10. While, seemingly, there's nothing wrong with deploying RAID 1 or RAID 10 configurations, they do add cost to the overall solution by requiring 2x the initial capacity and thus 2x the cost. These types of configurations do protect against a variety of Dual disk failure scenarios, however, they do not protect against every Dual disk failure scenario.
So lets look what is the probability of a Double disk failure using RAID 10. Below we have a 4 disk RAID 10 Raid group:

Here, we have 6 potential dual disk failure scenarios shown by the various arrows. Two of these failures scenarios are fatal (i.e Both disks that hold same mirrored block on either side, fail). So the probability of a fatal double disk failure is 2/6 or 33%. or 1/n-1 disks. Yow!!!
So let me see...2x capacity at 2x the cost so you can, potentially, survive 66% of the failures!!! Clearly there's a winner and a loser here and you can guess who's who.
With Netapp's patented RAID-DP solution you are guaranteed protection against a double disk failure at a fraction of RAID 1 (2N) or RAID 10 (2N) capacity (RAID-DP=N+2 parity drives) and at a fraction of the cost.
Furthermore, RAID-DP is very flexible and allows our customers to non-disruptively change from an existing RAID-4 configuration to a RAID-DP one and vice versa, on-the-fly.
iSCSI offers implementation choices
Over the past year iSCSI has picked up significant steam, particularly in regional and remote Datacenters which contain a large number of DAS. To date the majority of implementation involve primarily Windows servers even though Linux has lately shows as the next iSCSI frontier.
For those of you who may not be aware, there are several ways to implement iSCSI. First and foremost you need an array with Native iSCSI capabilities or an FC-iSCSI gateway in-front of the array that will convert FC frames into iSCSI packets. Needless to say there's some overhead associated with the latter approach since there's protocol conversion that has to occur in the gateway.
On the host side, there are several choices:
1) Most Operating systems vendors offer iSCSI software initiators free of charge than be used in conjuction with a regular NIC card to implement iSCSI. Windows, Linux, Netware, HP-UX, AIX and Solaris 10 offer such software initiators. These initiators are extremely easy to deploy and have no real cost since most servers today ship with at least 2 Gigabit Ethernet ports. One of the potential drawbacks of this implementation is the CPU overhead due to the TCP/IP and iSCSI processing. I say "potential" because in my 3 year experience with iSCSI i've seen exactly one occurrence of this and it was directly related to the age of the server, the number of CPUs, and more importantly the CPU processing power. To address situations like this, the 2nd iSCSI implementation choice is via the use of iSCSI TOE cards
2) iSCSI TOE (TCP/IP Offload Engine)cards are specialized cards that are used with the iSCSI Software initiator on a host and provide TCP/IP offload from the host's CPU to a chip on the card. This allows the CPU to focus mostly in processing application requests. TOE cards can also be used as regular NICs in addition to servicing iSCSI traffic. However, with the TOE approach all iSCSI processing still occurs on the host CPU. That's where iSCSI HBAs come into play. The average price for a dual ported TOE is around $600-700.
3) iSCSI HBAs are similar to FC HBAs in that they offload all protocol processing overhead from the host CPU to the card itself, thus allowing the CPU to focus entirely on application processing. The average cost of a single ported iSCSI HBA is somewhere between $500-600.
Which one of the methods you choose to implement is strictly dependent on your servers and more importantly the number of CPUs as well as the CPU processing power. For new servers, the last 2 approaches maybe a stretch since modern servers have a tremendous amount processing power and thus any overhead will most likely go un-noticed. However, for older servers, or for servers whith a current CPU utlization of > 70% then deploying a TOE or an iSCSI HBA will make sense.
The nice thing about iSCSI is that it offers choices, and flexibility in that it allows folks to reap the benefits of networked storage in a cost effective manner.
Lost Writes
One of the best kept secrets of the Storage industry is about "lost writes". Some of you are probably not aware of this, mostly because it's a rare condition, but in my mind if it happens once, that's one too many times, especially since it compromises the integrity of your data.
There are cases where a drive will signal to the application that a block has been written to disk when in fact, it either hasn't or it has been written to the wrong place. Yikes!!!
Most vendors I know of offer no such protection, therefore a single occurrence, will have a direct effect on the integrity of the data followed by necessary application recovery procedures.
The only vendor I know of that offers "lost write" protection is Netapp with the DataONTAP 7.x release. Again, the goodness of WAFL comes into play here. Because Netapp has the ability to control both the RAID and the filesystem, DataONTAP provides the unique ability to catch errors such as this and recover. Along with the block checksum DataONTAP also stores WAFL metadata(i.e inode # of a file containing the block) that provide the ability to verify the validity of a block being read. So if the block being read does not match what WAFL expects, the data gets reconstructed thus providing solid data protection scheme even for a unlikely scenario such as this.
There are cases where a drive will signal to the application that a block has been written to disk when in fact, it either hasn't or it has been written to the wrong place. Yikes!!!
Most vendors I know of offer no such protection, therefore a single occurrence, will have a direct effect on the integrity of the data followed by necessary application recovery procedures.
The only vendor I know of that offers "lost write" protection is Netapp with the DataONTAP 7.x release. Again, the goodness of WAFL comes into play here. Because Netapp has the ability to control both the RAID and the filesystem, DataONTAP provides the unique ability to catch errors such as this and recover. Along with the block checksum DataONTAP also stores WAFL metadata(i.e inode # of a file containing the block) that provide the ability to verify the validity of a block being read. So if the block being read does not match what WAFL expects, the data gets reconstructed thus providing solid data protection scheme even for a unlikely scenario such as this.
Sunday, April 30, 2006
SATA drives and 520bps formatting
Almost all vendors who use Fibre Channel drives format them using 520bps. 512 bytes are used to store data and 8 bytes are used to store a Block checksum (BCS) of the previous 512 bytes as a protection scheme.
However, PATA/SATA drives have a fixed format of 512bps that can't be changed. So one question you need to ask your vendor, if you deploy SATA drives, is if and how they implement Block checksums on SATA drives. One vendor I know of, HDS, implements a technique called read-after-write. What they do is, that after they write to the drive, they read back the data and verify it. That also means that the for each write there are 2 IOs from disk. One write and one read. So for heavy write ops the overhead can be significant.
Netapp has a very nice technique largely attributed to the flexibility of DataONTAP and WAFL. Netapp implements BCS on SATA drives!!! How you say?
Netapp uses what's called an 8/9ths scheme. A WAFL block is 4k. Because Netapp has complete control of RAID and the filesystem, what ONTAP does is to use every 9th 512 byte sector as an area that contains the checksum of the previous 8 512b sectors (4k WAFL block). As a result of this RAID treats the disk as if it were formatted with 520bps. Thus there's no need to immediately read back the data after its written.
However, PATA/SATA drives have a fixed format of 512bps that can't be changed. So one question you need to ask your vendor, if you deploy SATA drives, is if and how they implement Block checksums on SATA drives. One vendor I know of, HDS, implements a technique called read-after-write. What they do is, that after they write to the drive, they read back the data and verify it. That also means that the for each write there are 2 IOs from disk. One write and one read. So for heavy write ops the overhead can be significant.
Netapp has a very nice technique largely attributed to the flexibility of DataONTAP and WAFL. Netapp implements BCS on SATA drives!!! How you say?
Netapp uses what's called an 8/9ths scheme. A WAFL block is 4k. Because Netapp has complete control of RAID and the filesystem, what ONTAP does is to use every 9th 512 byte sector as an area that contains the checksum of the previous 8 512b sectors (4k WAFL block). As a result of this RAID treats the disk as if it were formatted with 520bps. Thus there's no need to immediately read back the data after its written.
Queue Depths
I get this question a lot from my customers and prospects. How many hosts can I can connect to array X? Vendor Y claims his array can connect 512 hosts. Vendor Z claims his array can connect up to 1024 hosts.
In general, there's a lot of confusion regarding the capability of a single array and the number of hosts it can adequately support. The numbers stated above are purely theoretical in nature and no vendor has connected nor can they point you to a customer of theirs with this many host connections to an array.
In general, the number of hosts an array can adequately support is dependent upon several things. One, is the available Queues per Physical Storage Port. Secondly, is the number the Storage Ports and third, is the array's available bandwidth.
The number of outstanding IOs per physical storage port has a direct impact on performance and scalability. Storage ports within arrays have varying queue depths, from 256 Queues, to 512, to 1024, to 2048 per port. The number of initiators (aka HBAs) a single storage port can support is directly related to the storage port's available queues.
For example a port with 512 queues and a typical LUN queue depth of 32 can support up to:
512 / 32 = 16 LUNs on 1 Initiator (HBA) or 16 Initiators(HBAs) with 1 LUN each or any combination not to exceed this number.
Configurations that exceed this number are in danger of returning QFULL conditions. A QFULL condition signals that the target/storage port is unable to process more IO requests and thus the initiator will need to throttle IO to the storage port. As a result of this, application response times will increase and IO activity will decrease. Typically, initiators will throttle I/O and will gradually start increasing it again.
While most OSes can handle QFULL conditions gracefully, some mis-interpret QFULL conditions as I/O errors. From what I recall, AIX is such an animal, where after three successive QFULL conditions an I/O error will occur.
Having said all this, since FC traffic is by nature bursty, the probability that all initiators will do a fast load on the LUNs at the same with the same I/O characteristics, to the same storage port is probably low, however, it's possible and it happens from time to time. So watch out and plan ahead.
The key message to remember is that when someone tells you that they can connect an enormous number of hosts to their disk array, is to ask them the queue depth setting on the host and the available queue depth per storage port. That's the key. For random I/O, a typical LUN queue depth setting is anywhere from 16-32. For sequential 8 is a typical setting.
So lets do an example:
An 8 port array with 512 queues per storage port and a host queue depth setting of 32 will be able to connect up to:
( 8 x 512) / 32 = 128 single connected hosts or 64 Dually connected hosts.
The fan-out ratio here is 16/1. That means 16 initiators per storage port. Depending on the I/O characteristics this number may or may not be high. The industry average is around 7-8/1 but I've seen then as high as 20/1. It all depends on the I/O and nature of it. If you're doing random I/O with a small block size chances are you'll be OK, but if the I/O is sequential, then bandwidth is critical and the fan-out ratio will need to come down. The application performance requirements will dictate the ratio.
In general, there's a lot of confusion regarding the capability of a single array and the number of hosts it can adequately support. The numbers stated above are purely theoretical in nature and no vendor has connected nor can they point you to a customer of theirs with this many host connections to an array.
In general, the number of hosts an array can adequately support is dependent upon several things. One, is the available Queues per Physical Storage Port. Secondly, is the number the Storage Ports and third, is the array's available bandwidth.
The number of outstanding IOs per physical storage port has a direct impact on performance and scalability. Storage ports within arrays have varying queue depths, from 256 Queues, to 512, to 1024, to 2048 per port. The number of initiators (aka HBAs) a single storage port can support is directly related to the storage port's available queues.
For example a port with 512 queues and a typical LUN queue depth of 32 can support up to:
512 / 32 = 16 LUNs on 1 Initiator (HBA) or 16 Initiators(HBAs) with 1 LUN each or any combination not to exceed this number.
Configurations that exceed this number are in danger of returning QFULL conditions. A QFULL condition signals that the target/storage port is unable to process more IO requests and thus the initiator will need to throttle IO to the storage port. As a result of this, application response times will increase and IO activity will decrease. Typically, initiators will throttle I/O and will gradually start increasing it again.
While most OSes can handle QFULL conditions gracefully, some mis-interpret QFULL conditions as I/O errors. From what I recall, AIX is such an animal, where after three successive QFULL conditions an I/O error will occur.
Having said all this, since FC traffic is by nature bursty, the probability that all initiators will do a fast load on the LUNs at the same with the same I/O characteristics, to the same storage port is probably low, however, it's possible and it happens from time to time. So watch out and plan ahead.
The key message to remember is that when someone tells you that they can connect an enormous number of hosts to their disk array, is to ask them the queue depth setting on the host and the available queue depth per storage port. That's the key. For random I/O, a typical LUN queue depth setting is anywhere from 16-32. For sequential 8 is a typical setting.
So lets do an example:
An 8 port array with 512 queues per storage port and a host queue depth setting of 32 will be able to connect up to:
( 8 x 512) / 32 = 128 single connected hosts or 64 Dually connected hosts.
The fan-out ratio here is 16/1. That means 16 initiators per storage port. Depending on the I/O characteristics this number may or may not be high. The industry average is around 7-8/1 but I've seen then as high as 20/1. It all depends on the I/O and nature of it. If you're doing random I/O with a small block size chances are you'll be OK, but if the I/O is sequential, then bandwidth is critical and the fan-out ratio will need to come down. The application performance requirements will dictate the ratio.
Subscribe to:
Posts (Atom)
