Folks,
This is my last post on this blog as NetApp has graciously offered several of us the opportunity to use Typepad as the hosting service.
So, starting today I will be blogging using the new hosting service. The new Blog is titled Storage Nuts N' Bolts and so I hope to see you there.
Friday, November 09, 2007
Monday, October 22, 2007
Solaris 10 iSCSI configured with Dynamic Discovery
Recently we went thru re-IPing all of our servers and storage arrays in our office. For the most part everything went fine with the exception of a Solaris 10 U3 server I was running iSCSI on.
After I got thru the steps of changing the server's IP address, gateway and DNS entries I rebooted the server. Upon reboot, I noticed a flurry of non-stop error messages at the server's console:
Sep 30 18:37:37 longhorn iscsi: [ID 286457 kern.notice] NOTICE: iscsi connection(8) unable to connect to target SENDTARGETS_DISCOVERY (errno:128)Sep 30 18:37:37 longhorn iscsi: [ID 114404 kern.notice] NOTICE: iscsi discovery failure - SendTargets (0xx.0xx.0xx.0xx)
As a result of this, I was never able to get a login prompt either at the console or via telnet even though I could succesfuly ping the server's new IP address. What the message above indicates is that the initiator issues a SendTargets and waits for the Target to respond with its Targets. To my surprise there's NO timeout and the initiator will try this process indefinately. In fact, just for kicks, I left it trying for an hour and 45'.
That also means that you will be locked out of the server, as attempting to boot into single user mode results in the exact same behavior.
To get around this problem you have 2 options even though option #2, for some, may not be an option.
Option 1
--------
a) Boot from a Solaris cdrom
b) mount /dev/dsk/c#t#d#s0 /a
c) cd /a/etc/iscsi
d) Remove or rename *.dbc and *.dbp files (iscsi not configured any longer)
e) Reboot the server
f) Use iscsiadm and configure the Solaris server with Static discovery (static-config) so you don't get into this situation again
Option 2
---------
a) Change back to the old Target IP address
b) That will enable you to reboot the server
c) Reconfigure the server to use static-config by specifying the target-name, new Target-ip-address and port-number
d) Change the Target IP address to the new one
I followed Option #1 because #2 was not really not an option for us. So the morale of the story is that you may want to consider static-discovery on Solaris with iSCSI.
After I got thru the steps of changing the server's IP address, gateway and DNS entries I rebooted the server. Upon reboot, I noticed a flurry of non-stop error messages at the server's console:
Sep 30 18:37:37 longhorn iscsi: [ID 286457 kern.notice] NOTICE: iscsi connection(8) unable to connect to target SENDTARGETS_DISCOVERY (errno:128)Sep 30 18:37:37 longhorn iscsi: [ID 114404 kern.notice] NOTICE: iscsi discovery failure - SendTargets (0xx.0xx.0xx.0xx)
As a result of this, I was never able to get a login prompt either at the console or via telnet even though I could succesfuly ping the server's new IP address. What the message above indicates is that the initiator issues a SendTargets and waits for the Target to respond with its Targets. To my surprise there's NO timeout and the initiator will try this process indefinately. In fact, just for kicks, I left it trying for an hour and 45'.
That also means that you will be locked out of the server, as attempting to boot into single user mode results in the exact same behavior.
To get around this problem you have 2 options even though option #2, for some, may not be an option.
Option 1
--------
a) Boot from a Solaris cdrom
b) mount /dev/dsk/c#t#d#s0 /a
c) cd /a/etc/iscsi
d) Remove or rename *.dbc and *.dbp files (iscsi not configured any longer)
e) Reboot the server
f) Use iscsiadm and configure the Solaris server with Static discovery (static-config) so you don't get into this situation again
Option 2
---------
a) Change back to the old Target IP address
b) That will enable you to reboot the server
c) Reconfigure the server to use static-config by specifying the target-name, new Target-ip-address and port-number
d) Change the Target IP address to the new one
I followed Option #1 because #2 was not really not an option for us. So the morale of the story is that you may want to consider static-discovery on Solaris with iSCSI.
Wednesday, October 17, 2007
VMware over NFS: Backup tricks...continued
There have been a couple of questions on how to do file level backups of a Linux vmdk over NFS. I described the process for a Windows vmdk in a previous article here
In order to do this for a Linux vmdks you need to do the following:
- Create a Flexclone of the NFS volume from a snapshot
- Mount the flexclone to your linux server
- Do not use the read-only mount option as linux requires read-write access
- Specify -t ext3 as the mount option (you can get the FS type per partition by "df -T")
- Remember to use fdisk -lu to get the starting sector for each partition
Multiply the starting sector x 512 bytes and specify the result in the "offset" field of the mount command

One reader asked a good question regarding Windows. The question was how to do file level backups of partitioned windows vmdks? The answer to this lays in the offset parameter of the mount option
What you need to do in a scenario like this is:
- Run msinfo32.exe in your Windows vm
- Go to Components -> Storage -> Disks
- Note the Partition Starting offsets and specify them as part of the mount option.
Friday, September 21, 2007
Demos from VMworld
I promised last week to post some links to some of the demos we ran after VMworld was over. So for those who have not seen them here they are. There's audio as well so plug in your headsets.
1) VDI on Netapp over NFS
2) Eliminate duplicate data with A-SIS in a VMware environment
There are also several presentations and technical whitepapers at TechONTAP site which you may find very useful.
1) VDI on Netapp over NFS
2) Eliminate duplicate data with A-SIS in a VMware environment
There are also several presentations and technical whitepapers at TechONTAP site which you may find very useful.
Tuesday, September 11, 2007
VMware on NFS: Backup Tricks
Ok, so if you've decided to use VMware over NFS. Then there's always some guy who's find something to neatpick about and so he'll say "Well, can't run VCB on NFS". He's right but I don't see this as an issue? Sometimes it takes imagination to find a solution to a challenge.
Using NFS as a protocol on VMware you have similar choices and flexibility as with VCB and you can mount the NFS volume or a snapshot of the volume on a server other an ESX...Other = Linux in this case.
So if you are deploying VMware on NFS here's a way to backup whole VMDK images or files within VMDKs using Netapp Snapshots given that the Snapshots are accessible to the NFS client.
Mind you that with this approach you do all kinds of cool things and not just backups without impacting the ESX host. You can also restore, or you could also provision...
So here's the process:
1) Install the Linux NTFS driver if it's not already in your Linux built.
Note: For RHEL and Fedora installs click on the About RedHat/FC RPMs
2) Mount the export onto your linux server
# mount xx.xx.xx.xx:/vol/nfstest /mnt/vmnfs
So now you can backup VMDK images or you can drill into the .snapshot directory and back them up from there.
Next step is to backup files within VMDKs by accessing the snapshot...and you get to pick from which one. For this test, I select from the hourly.3 the snapshot named testsnap
3) Mount the VMDK as a loopback mount specifying the starting offset (32256) and NTFS file system type
# mount /mnt/nfstest/.snapshot/hourly.3/testsnap/nfs-flat.vmdk /mnt/vmdk -o ro,loop=/dev/loop2,offset=32256 -t ntfs
Here's your NTFS disk as seen from Linux:
# cd /mnt/vmdk
# ls -l
total 786844
dr-x------ 1 root root 0 Dec 19 03:03 013067c550e7cf93cc24
-r-------- 1 root root 0 Sep 11 2006 AUTOEXEC.BAT-
r-------- 1 root root 210 Dec 18 21:00 boot.ini
-r-------- 1 root root 0 Sep 11 2006 CONFIG.SYS
dr-x------ 1 root root 4096 Dec 18 21:10 Documents and Settings
-r-------- 1 root root 0 Sep 11 2006 IO.SYS
-r-------- 1 root root 0 Sep 11 2006 MSDOS.SYS
-r-------- 1 root root 47772 Mar 25 2005 NTDETECT.COM
-r-------- 1 root root 295536 Mar 25 2005 ntldr
-r-------- 1 root root 805306368 Mar 13 16:42 pagefile.sys
dr-x------ 1 root root 4096 Sep 11 2006 Program Files
dr-x------ 1 root root 0 Sep 11 2006 RECYCLER
dr-x------ 1 root root 0 Sep 11 2006 System Volume Information
dr-x------ 1 root root 0 Dec 19 00:35 tempd
r-x------ 1 root root 65536 Mar 13 17:41 WINDOWS
dr-x------ 1 root root 0 Sep 11 2006 wmpub
password: cbvfor9v9r
Using NFS as a protocol on VMware you have similar choices and flexibility as with VCB and you can mount the NFS volume or a snapshot of the volume on a server other an ESX...Other = Linux in this case.
So if you are deploying VMware on NFS here's a way to backup whole VMDK images or files within VMDKs using Netapp Snapshots given that the Snapshots are accessible to the NFS client.
Mind you that with this approach you do all kinds of cool things and not just backups without impacting the ESX host. You can also restore, or you could also provision...
So here's the process:
1) Install the Linux NTFS driver if it's not already in your Linux built.
Note: For RHEL and Fedora installs click on the About RedHat/FC RPMs
2) Mount the export onto your linux server
# mount xx.xx.xx.xx:/vol/nfstest /mnt/vmnfs
So now you can backup VMDK images or you can drill into the .snapshot directory and back them up from there.
Next step is to backup files within VMDKs by accessing the snapshot...and you get to pick from which one. For this test, I select from the hourly.3 the snapshot named testsnap
3) Mount the VMDK as a loopback mount specifying the starting offset (32256) and NTFS file system type
# mount /mnt/nfstest/.snapshot/hourly.3/testsnap/nfs-flat.vmdk /mnt/vmdk -o ro,loop=/dev/loop2,offset=32256 -t ntfs
Here's your NTFS disk as seen from Linux:
# cd /mnt/vmdk
# ls -l
total 786844
dr-x------ 1 root root 0 Dec 19 03:03 013067c550e7cf93cc24
-r-------- 1 root root 0 Sep 11 2006 AUTOEXEC.BAT-
r-------- 1 root root 210 Dec 18 21:00 boot.ini
-r-------- 1 root root 0 Sep 11 2006 CONFIG.SYS
dr-x------ 1 root root 4096 Dec 18 21:10 Documents and Settings
-r-------- 1 root root 0 Sep 11 2006 IO.SYS
-r-------- 1 root root 0 Sep 11 2006 MSDOS.SYS
-r-------- 1 root root 47772 Mar 25 2005 NTDETECT.COM
-r-------- 1 root root 295536 Mar 25 2005 ntldr
-r-------- 1 root root 805306368 Mar 13 16:42 pagefile.sys
dr-x------ 1 root root 4096 Sep 11 2006 Program Files
dr-x------ 1 root root 0 Sep 11 2006 RECYCLER
dr-x------ 1 root root 0 Sep 11 2006 System Volume Information
dr-x------ 1 root root 0 Dec 19 00:35 tempd
r-x------ 1 root root 65536 Mar 13 17:41 WINDOWS
dr-x------ 1 root root 0 Sep 11 2006 wmpub
The nice thing about the loopback mount is that Linux will see a VMDK's content for any filesystem it recognizes...so now you can backup Windows and Linux VMs.
Here's a more indepth presentation on VMware over NFS including the backup trick from Peter Learmonth as well as a customer presentation from the VMworld breakout sessions. Login and passwords are proivided below:
user name: cbv_reppassword: cbvfor9v9r
Cheers
Friday, September 07, 2007
VMware over NFS
My background is Fibre Channel and since 2003 I've followed iSCSI very closely. In fact, for years I have never paid much attention to other protocols until recently. For a long time I felt that FC was good for everything, which sounds weird if you consider who my employer is but then again, NetApp didn't hire me for my CIFS or NFS prowess. I was hired to drive adoption of NetApp's Fibre Channel and iSCSI offerings as well as the help prospects realize the virtues of a Unified Storage Architecture.
And speaking of Unified architectures leads me to VMware which represents to servers exactly what NetApp represents to storage. A Unified architecture with choices, flexibility, and centralized management without shoving a specific protocol down someones throat.
Close to 90% of the VI3 environments today are deployed over FC and of that %, based on experience, I'd say that 90% are using VMFS, VMware's clustered filesystem.
If you are dealing 2-3 clustered ESX, these types of deployments are not very complex. However, the complexity starts to increase exponentially as the number of servers in a VMware Datacenter start to multiply. RAID Groups, LUNs, LUN IDs, Zones, Zone management, HBAs, queue depths, VMFS Datastores, RDMs, multipathing settings etc.
Then the question comes up...VMFS LUNs or RDMs. How's my performance is going to be with 8-10 VMs on a VMFS LUN and a single Disk I/O queue? What if I take the RDM route and later one i run out of LUNs?
Way to many touch points, way too many things to pay attention to, way to many questions.
Well, there's help...NFS. I've recently had to the opportunity to play with NFS in my environment over VMware, and I can tell you, you are missing out if you at least do not consider it and test it for your environment.
Here's what I have found out with NFS and I'm not the only one:
- Provisioning is a breeze
- You get the advantage of VMDK thin Provisioning since it's the default setting over NFS
- You can expand/decrease the NFS volume on the fly and realize the effect of the operation on the ESX server with the click of the datastore "refresh" button.
- You don't have to deal with VMFS or RDMs so you have no dilemma here
- No single disk I/O queue, so your performance is strictly dependent upon the size of the pipe and the disk array.
- You don't have to deal with FC switches, zones, HBAs, and identical LUN IDs across ESX servers
- You can restore (at least with NetApp you can), multiple VMs, individual VMs, or files within VMs.
- You can instantaneously clone (NetApp Flexclone), a single VM, or multiple VMs
- You can also backup whole VMs, or files within VMs
People may find this hard to believe, but the performance over NFS is actually better than FC or iSCSI not only in terms of throughtput but also in terms of latency. How can this be people ask? FC is 4Gb and Ethernet is 1Gb. I would say that this is a rather simplistic approach to performance. What folks don't realize is that:
- ESX server I/O is small block and extremely random which means that bandwidth matters little. IOs and response time matter a lot.
- You are not dealing with VMFS and a single managed disk I/O queue.
- You can have a Single mount point across multiple IP addesses
- You can use link aggregation IEEE 802.3ad (NetApp multimode VIF with IP aliases)
Given that server virtualization has incredible ramifications on storage in terms of storage capacity requirements, storage utilization and thus storage costs, I believe that the time where folks will warm up to NFS is closer than we think. With NFS you are thin provisioning by default and the VMDKs are thin as well. Plus any modification on the size of the NFS volume in terms of capacity is easily and immediately realized on the host side. Additionally, if you consider the fact that on average a VMFS volume is around 70-80% utilized (actually that maybe high) and the VMKD is around 70% you can easily conclude that your storage utilization is anywhere around from 49-56% excluding RAID overhead, then NFS starts to make a LOT of sense.
VMworld is next week and NetApp is a platinum sponsor. So, if you are attending, I would recommend you drop by Booth 701 and take a look at some incredibly exciting demos that have been put together showcasing the latest NetApp innovations with ESX server as well as VDI.
I'm hoping to be uploading the demo videos here next week or have links to them .
Thursday, June 07, 2007
SnapDrive for Windows 5.0 - Thin Provisioning and Space Reclamation
Back on July 11th 2006, I posted an article for Thin Provisioning. Today a reader made some very timely and appropriate comments around application support for thin provisioning and alerting and monitoring.
"I guess eventually OS and Apps have to start supporting thin provisioning, in terms of how they access the disk, and also in terms of instrumentation for monitoring and alerting"
Back in that article I had written that I would not deploy thin provisioning for new applications for which I had no usage metrics and for applications which would write, delete or quickly re-write data in a LUN. Here's why, up until now, I would avoid the latter scenario.
The example below attempts to illustrate this point.
Lets assume I have thinly provisioned a 100GB LUN to a Windows server.
I now fill in 50% of the LUN with data. Upon doing this, capacity utilization, from a filesystem standpoint is 50%, and from an array perspective is also 50%.
I then proceed to completely fill the LUN. Now, the filesystem and array capacity utilization are both at 100%.
Then I decide to delete 50% of the data in the LUN. What’s the filesystem and array capacity utilization? Folks are quick to reply that it’s at 50% but that is a partially correct answer. The correct answer is that filesystem utilization is at 50% but array utilization is still at 100%. The reason is that even though NTFS has freed some blocks upon deleting half of the data in the LUN, from an array perspective, these blocks still reside on the disk as there is no way for the array to know that the data is no longer needed.
So now, if more data is written in the LUN, there is no guarantee that the filesystem, will use the exact same blocks it freed previously to write the new data. That means that in a Thin Provisioning scenario, this behavior may trigger a storage allocation on the array when in fact such allocation may not be needed. So now, we’re back to square one in attempting to solve the exact same storage over-allocation challenge.
SnapDrive for Windows 5.0
With the int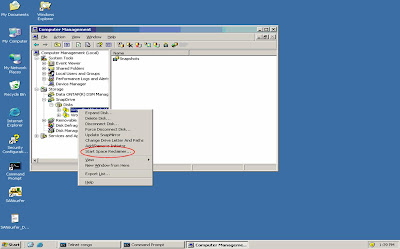 roduction of SnapDrive for Windows 5.0, Network Appliance, introduced a feature called Space Reclamation.
roduction of SnapDrive for Windows 5.0, Network Appliance, introduced a feature called Space Reclamation.
The idea is to provide integration between NTFS and WAFL via a mechanism that will notify WAFL when NTFS has freed blocks so that WAFL, in turn, can reclaim these blocks and mark them as free.
Within SnapDrive 5.0 the space reclamation process can be initiated either via the GUI or the CLI. Upon initiating the space reclamation process, a pop-up window for the given LUN will inform the Administrator as to whether or not a space reclamation operation is needed, and if indeed, how much space will be reclaimed.
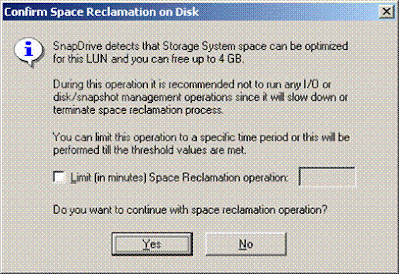 Additionally, the space reclamation process can be timed and the time window can be specified in minutes, 1-10080 minutes or 7 days, for the process to execute. Furthermore, there is no licensing requirement in order to utilize the Space Reclamation feature as it is bundled in with the recently released version of SnapDrive 5.0. However, the requirement is that the version of DataONTAP must be at 7.2.1 or later.
Additionally, the space reclamation process can be timed and the time window can be specified in minutes, 1-10080 minutes or 7 days, for the process to execute. Furthermore, there is no licensing requirement in order to utilize the Space Reclamation feature as it is bundled in with the recently released version of SnapDrive 5.0. However, the requirement is that the version of DataONTAP must be at 7.2.1 or later.
Performance is strictly dependent upon the number and the size of LUNs that are under the space reclamation process.
As a general rule, we recommend that the process is run during low I/O activity periods and when Snapshot operations such as snapshot create and snap restore are not in use.
While other competitors offer thin provisioning, Network Appliance, once again, has been the first to provide yet another innovative and important tool that helps our customers not only to safely deploy thin provisioning but also realize the benefits that derive from it.
"I guess eventually OS and Apps have to start supporting thin provisioning, in terms of how they access the disk, and also in terms of instrumentation for monitoring and alerting"
Back in that article I had written that I would not deploy thin provisioning for new applications for which I had no usage metrics and for applications which would write, delete or quickly re-write data in a LUN. Here's why, up until now, I would avoid the latter scenario.
The example below attempts to illustrate this point.
Lets assume I have thinly provisioned a 100GB LUN to a Windows server.
I now fill in 50% of the LUN with data. Upon doing this, capacity utilization, from a filesystem standpoint is 50%, and from an array perspective is also 50%.
I then proceed to completely fill the LUN. Now, the filesystem and array capacity utilization are both at 100%.
Then I decide to delete 50% of the data in the LUN. What’s the filesystem and array capacity utilization? Folks are quick to reply that it’s at 50% but that is a partially correct answer. The correct answer is that filesystem utilization is at 50% but array utilization is still at 100%. The reason is that even though NTFS has freed some blocks upon deleting half of the data in the LUN, from an array perspective, these blocks still reside on the disk as there is no way for the array to know that the data is no longer needed.
So now, if more data is written in the LUN, there is no guarantee that the filesystem, will use the exact same blocks it freed previously to write the new data. That means that in a Thin Provisioning scenario, this behavior may trigger a storage allocation on the array when in fact such allocation may not be needed. So now, we’re back to square one in attempting to solve the exact same storage over-allocation challenge.
SnapDrive for Windows 5.0
With the int
 roduction of SnapDrive for Windows 5.0, Network Appliance, introduced a feature called Space Reclamation.
roduction of SnapDrive for Windows 5.0, Network Appliance, introduced a feature called Space Reclamation.The idea is to provide integration between NTFS and WAFL via a mechanism that will notify WAFL when NTFS has freed blocks so that WAFL, in turn, can reclaim these blocks and mark them as free.
Within SnapDrive 5.0 the space reclamation process can be initiated either via the GUI or the CLI. Upon initiating the space reclamation process, a pop-up window for the given LUN will inform the Administrator as to whether or not a space reclamation operation is needed, and if indeed, how much space will be reclaimed.
Additionally, the space reclamation process can be timed and the time window can be specified in minutes, 1-10080 minutes or 7 days, for the process to execute. Furthermore, there is no licensing requirement in order to utilize the Space Reclamation feature as it is bundled in with the recently released version of SnapDrive 5.0. However, the requirement is that the version of DataONTAP must be at 7.2.1 or later.Performance is strictly dependent upon the number and the size of LUNs that are under the space reclamation process.

As a general rule, we recommend that the process is run during low I/O activity periods and when Snapshot operations such as snapshot create and snap restore are not in use.
While other competitors offer thin provisioning, Network Appliance, once again, has been the first to provide yet another innovative and important tool that helps our customers not only to safely deploy thin provisioning but also realize the benefits that derive from it.
Subscribe to:
Posts (Atom)
